Running an LLM locally

Working as a Principal Software Engineer. I have experience working on Java, Spring Boot, Go, Android Framework, OS, Shell scripting, and AWS. Experienced in creating scalable and highly available systems.
You can check my latest articles on AI on https://learncodecamp.net/category/ai/
In the ever-evolving landscape of natural language processing, large language models (LLMs) have emerged as powerful tools for understanding and generating human-like text. Running an LLM locally provides enthusiasts and developers with the flexibility to experiment, fine-tune, and explore the capabilities of these models without relying on external services. In this blog post, let's go through the process of setting up and running an LLM on your local machine.
In this blog post, we will learn how to run LLMs locally on your computer.
First, let's learn some keywords that are used in the LLM world
Tokenization:
Definition: The process of breaking down text into smaller units, called tokens. Tokens can be words, subwords, or even characters.
Importance: Tokenization is crucial for feeding input data into language models, as it converts continuous text into a format that the model can understand.
Pre-trained Models:
Definition: Models that have been trained on massive amounts of data before being fine-tuned for specific tasks. Pre-trained models capture general language patterns and knowledge.
Importance: Pre-trained models provide a starting point for various natural language processing tasks, saving time and computational resources.
Fine-tuning:
Definition: The process of training a pre-trained model on a specific dataset or for a specific task to adapt it to a particular use case.
Importance: Fine-tuning allows developers to customize pre-trained models for specific applications, improving performance on domain-specific data.
Inference:
Definition: The process of using a trained model to make predictions or generate outputs based on new, unseen data.
Importance: Inference is the phase where a model demonstrates its learned capabilities by processing real-world inputs and producing relevant outputs.
Tokenizer:
Definition: A tool or module responsible for tokenizing input text, breaking it down into tokens that can be understood by the model.
Importance: Tokenizers play a crucial role in preparing data for language models, ensuring that the input is in a suitable format for processing.
Embedding:
Definition: A numerical representation of words or tokens learned by a language model during training.
Importance: Embeddings capture semantic relationships between words and enable the model to understand the context and meaning of the input.
Hyperparameters:
Definition: Parameters set before the training process begins, influencing the learning process of the model.
Importance: Adjusting hyperparameters can significantly impact a model's performance and generalization to different tasks.
Attention Mechanism:
Definition: A component in neural networks that allows the model to focus on different parts of the input sequence when making predictions.
Importance: Attention mechanisms enhance the model's ability to consider relevant information while processing input data. Attention is All You Need
Hugging Face:
Definition: A popular platform and library that provides a collection of pre-trained models, including transformers for natural language processing tasks.
Importance: Hugging Face simplifies access to state-of-the-art language models and facilitates their integration into various projects.
SOTA (State-of-the-Art):
Definition: SOTA refers to the current highest level of performance or advancement in a particular field, often used to describe the best-known results or models at a given point in time.
Importance: It serves as a benchmark for evaluating the effectiveness of new models, algorithms, or techniques.
Transformer:
Definition: Transformer replaces recurrent or convolutional layers with self-attention mechanisms, allowing for parallelized computation and capturing long-range dependencies in data efficiently.
Importance: Transformers have become a cornerstone in deep learning, particularly in natural language processing. Their ability to process sequential data in parallel enhances training efficiency. Transformers, through self-attention, excel at understanding context and relationships within input sequences.
GPT (Generative Pre-trained Transformer):
Definition: GPT, or Generative Pre-trained Transformer, is a type of large language model architecture that utilizes transformer-based neural networks. Pre-trained on vast datasets, GPT excels in natural language understanding and generation tasks.
Importance: GPT revolutionized language processing by demonstrating exceptional capabilities in text generation, translation, and context comprehension. Its transformer architecture, with self-attention mechanisms, enables capturing intricate relationships in data.
Parameters
Definition: Parameters in LLMs refer to the weights and biases that the model learns during the training process. These numerical values determine the behavior and functionality of the model, allowing it to make predictions, generate text, or perform various natural language processing tasks.
Importance: The number of parameters in an LLM is a critical factor influencing its capacity to capture intricate language patterns and representations. A "20B parameters model," for instance, signifies a model with 20 billion learned parameters. Larger models with more parameters often demonstrate enhanced performance by capturing more nuanced relationships in language. However, the size of the model also comes with increased computational and resource demands, prompting a careful balance between model complexity, performance gains, and resource requirements in the development and deployment of LLMs.
These keywords provide a foundational understanding of the concepts and processes involved in the world of Large Language Models.
Choosing a Model
The first step in running an LLM locally is choosing a model. You can see the models on Hugging Face
Hugging Face, hosts a handy "Open LLM Leaderboard" that does just this, automatically evaluating open LLMs submitted to their Hub on several foundational benchmarks, measuring various reasoning and knowledge tasks in zero to 25-shot settings. Hugging Face’s four choice benchmarks are:
AI2 Reasoning Challenge - The ARC question set is partitioned into a Challenge Set and an Easy Set, where the Challenge Set contains only questions answered incorrectly by both a retrieval-based algorithm and a word co-occurence algorithm. The dataset contains only natural, grade-school science questions (authored for human tests), and is the largest public-domain set of this kind (7,787 questions).
HellaSwag - Can a Machine Really Finish Your Sentence? This contains tasks of commonsense natural language inference: given an event description such as "A woman sits at a piano," a machine must select the most likely followup: "She sets her fingers on the keys.
Massive Multitask Language Understanding - The test covers 57 tasks including elementary mathematics, US history, computer science, law, and more. To attain high accuracy on this test, models must possess extensive world knowledge and problem solving ability.
TruthfulQA - Measuring How Models Mimic Human Falsehoods, this measures whether a language model is truthful in generating answers to questions. The benchmark comprises 817 questions that span 38 categories, including health, law, finance and politics.
Now the first question, that comes to mind is if these evaluation data sets/ questions are available, then a new LLM can be trained on this data set, and then it will score well in the evaluation.
These things happen


Now the next question in choosing the LLM model is how much resources are needed to run a model.
For this, we will use a tool called LM Studio
It shows you clearly, how much RAM is required and how much disk space is needed to run the model.
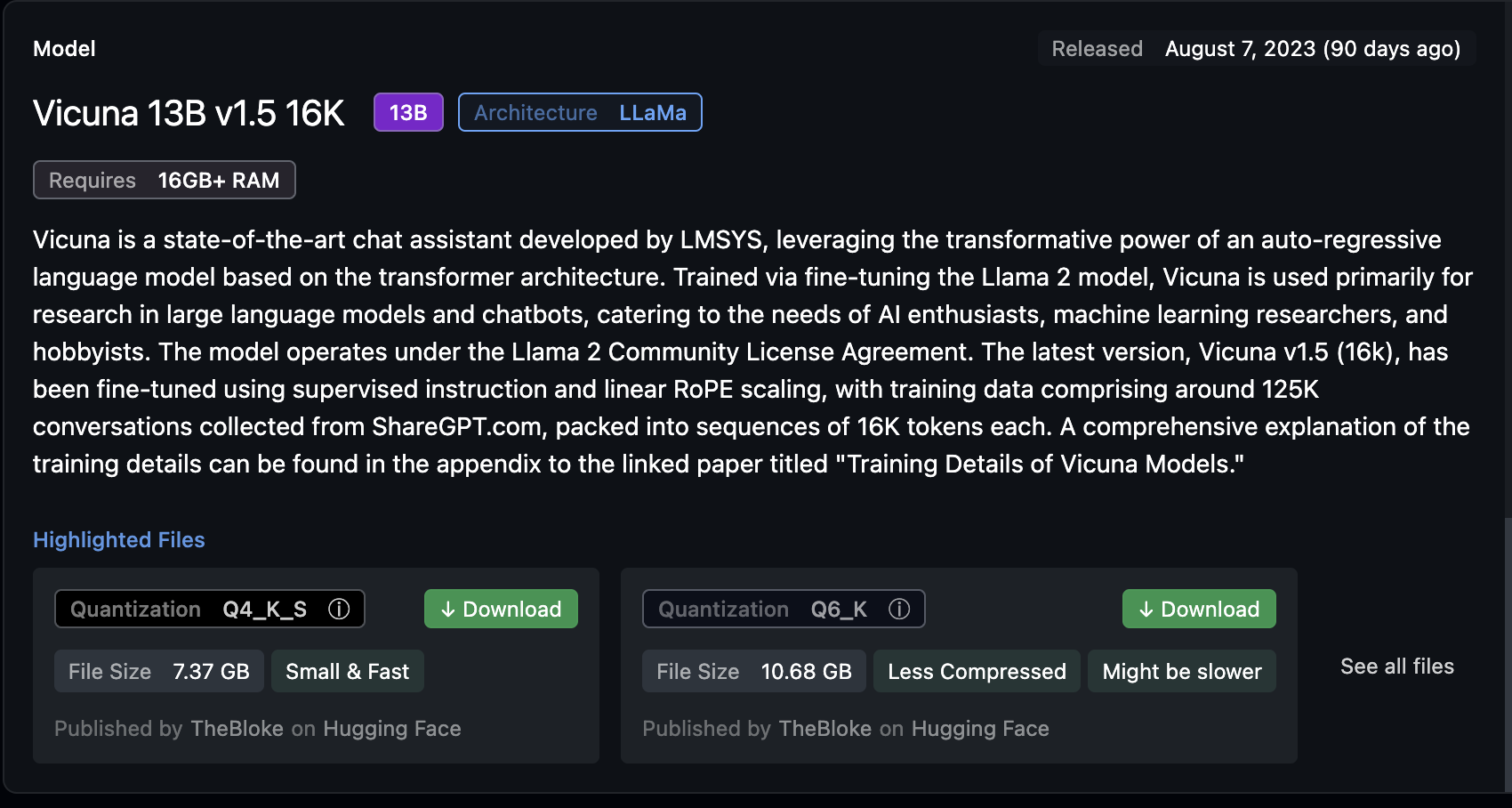
You can get this information from the model page on huggingface also
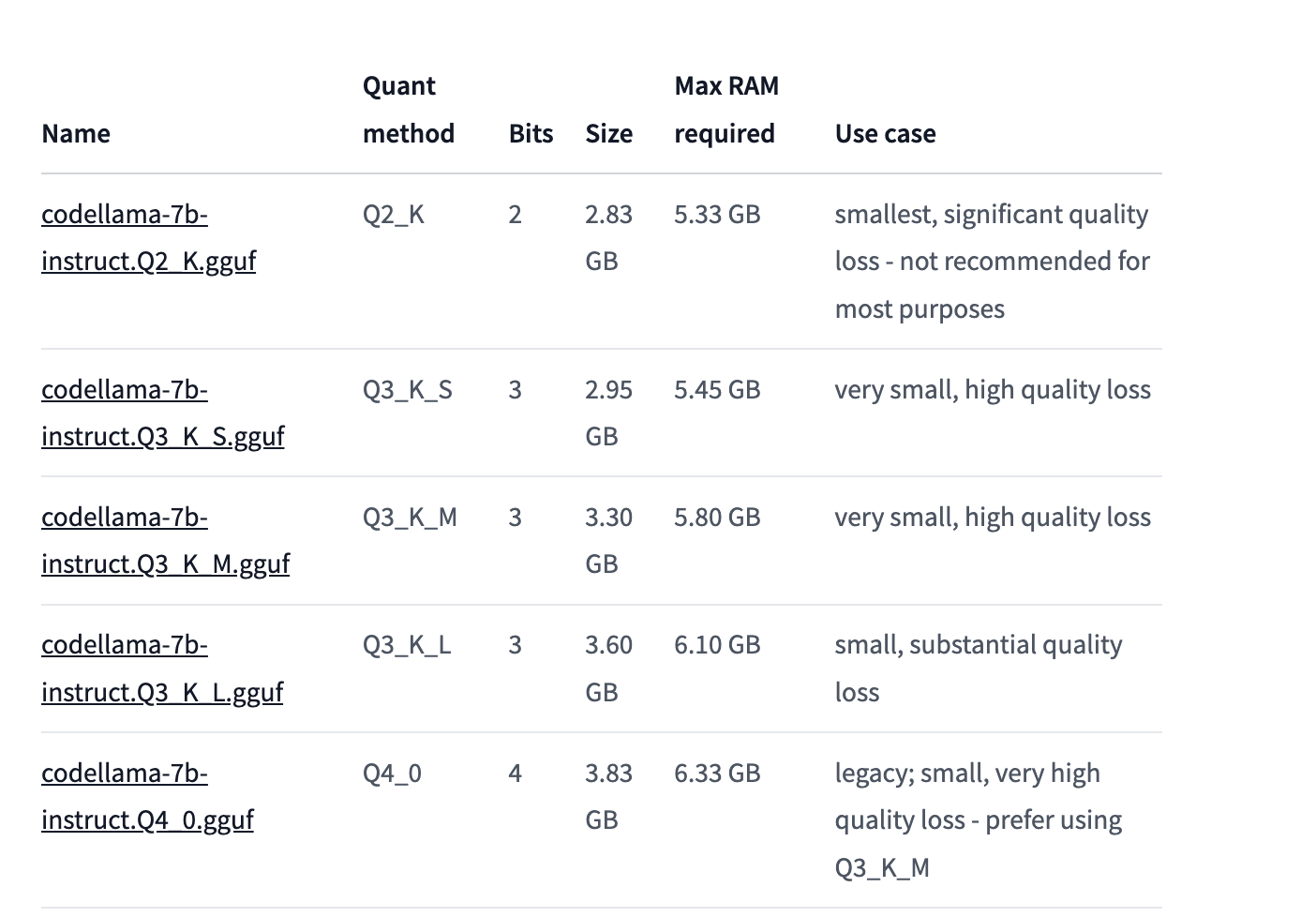
Now what is this Q3, Q4 and gguf
Q stands for Quantization
Quantized versions of models refer to models that have undergone quantization, which is a process of reducing the precision of the weights and activations in a neural network. The idea is to represent the numerical values with fewer bits (lower precision) without significantly sacrificing the model's performance. This can lead to reduced memory usage and faster inference, making it more efficient for deployment on devices with limited resources.
GGUF and GGML are file formats used for storing models for inference
GGML officially phased out, new format called GGUF · Issue #1370 · nomic-ai/gpt4all · GitHub
Q4 means 4 bit quantized version
- q4_0 = 32 numbers in chunk, 4 bits per weight, 1 scale value at 32-bit float (5 bits per value in average), each weight is given by the common scale * quantized value.
In simple language, more Quantized version means more loss, but the model will take less resources to run, similar to 144p video resolution compared to 1080p video resolution.
Now we have the app to run LLM and the model, let's download some models
Zephyr 7B β
Mistral 7B Instruct v0.1
With this you get an API server also so that you can use it via API, and this API style is compatible with OpenAI APIs, so you just have to replace the base urls, and then rest of your code that used OpenAI, can the remain same
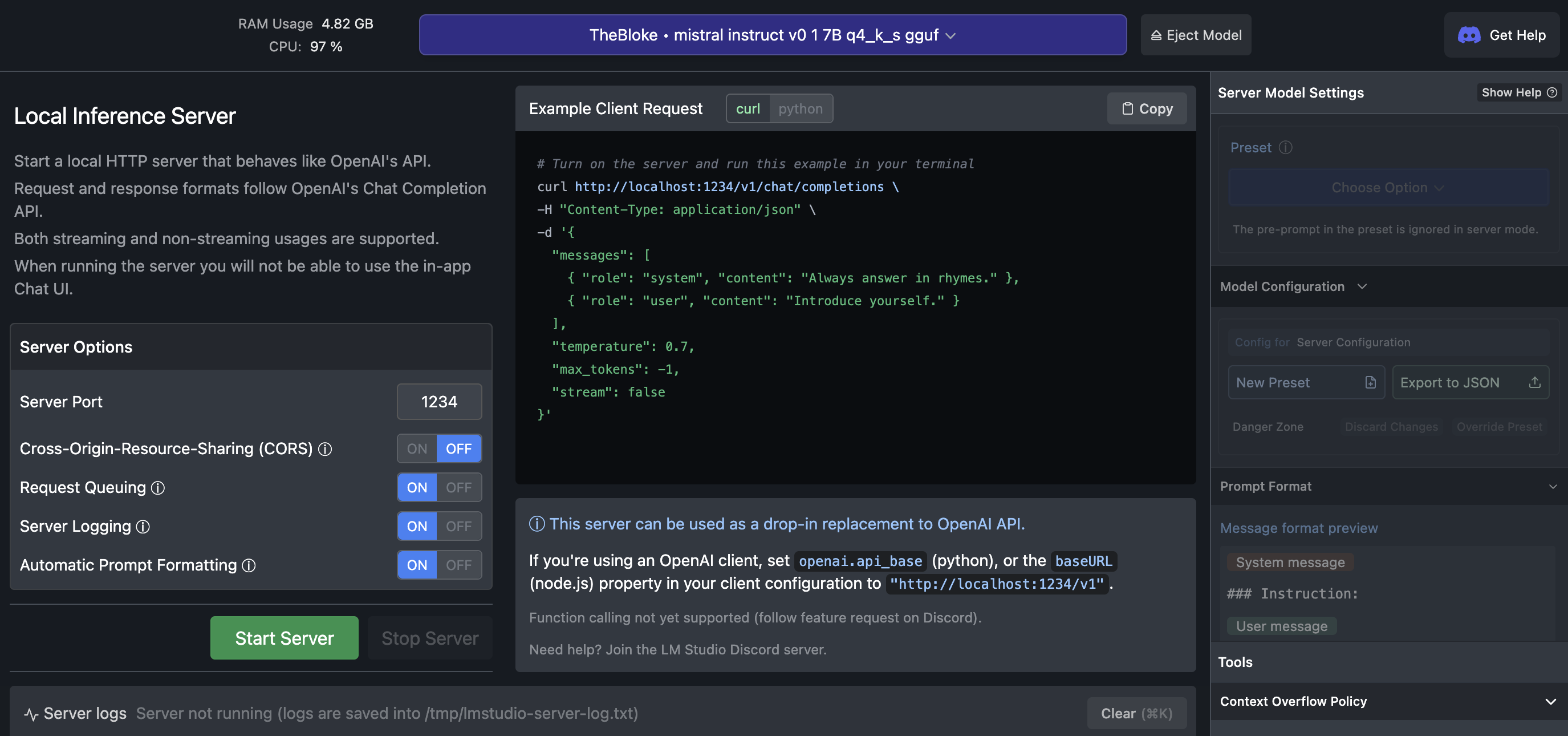
Now let's try asking some questions
with Zephyr
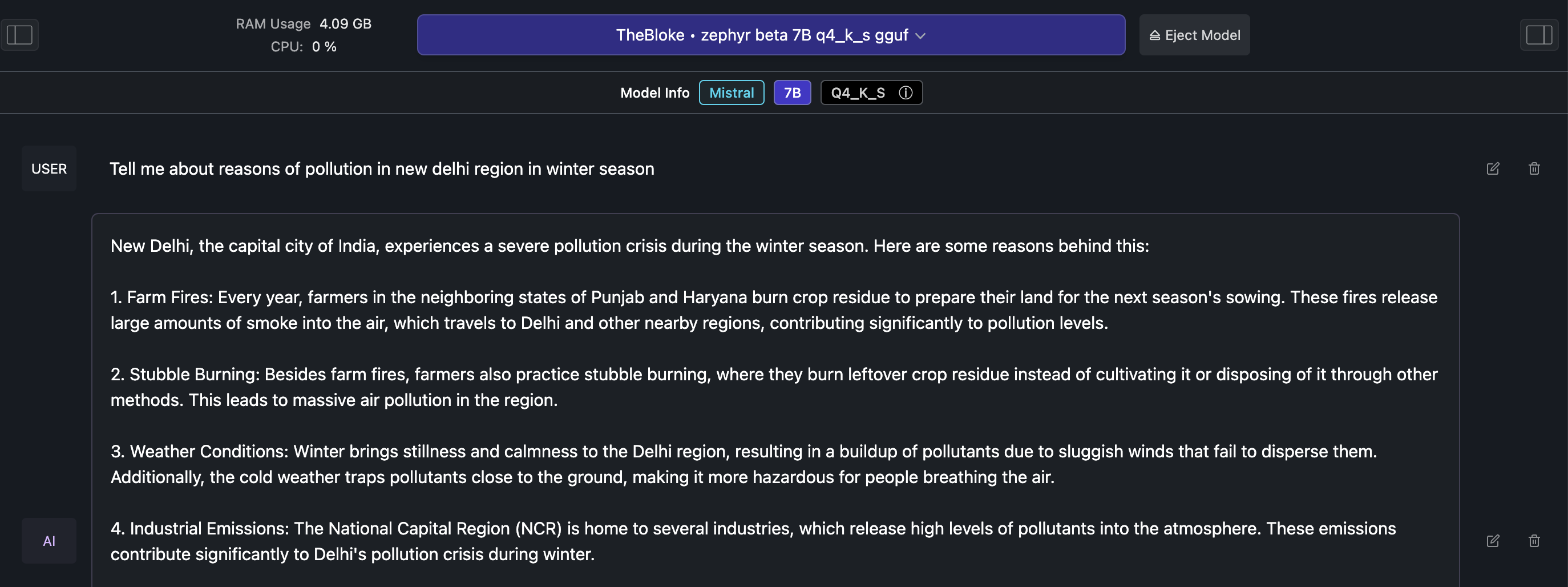
Same question from bard

Same question with Mistral
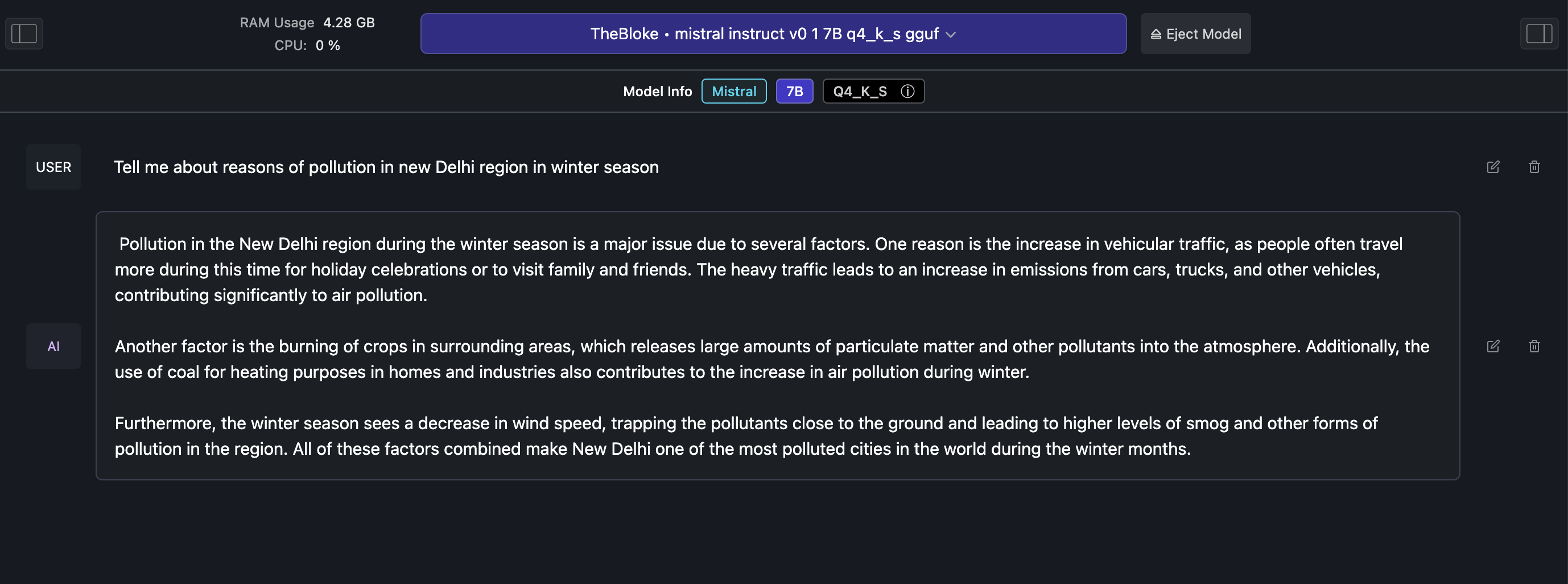
There are some other options also to run LLMs locally, we can try using ollama
We can run LLM from the command line.
ollama run mistral
It also exposes and API server, and we can call LLMs with APIs also.
If you liked this blog, you can follow me on twitter, and learn something new with me.




