Understanding Kafka Producer: How Partition Selection Works

Working as a Principal Software Engineer. I have experience working on Java, Spring Boot, Go, Android Framework, OS, Shell scripting, and AWS. Experienced in creating scalable and highly available systems.
Apache Kafka is a highly scalable and distributed streaming platform known for its fault-tolerant and high-throughput capabilities. One key component in the Kafka ecosystem is the producer client, responsible for publishing data to Kafka topics. In this blog post, we will dive into the internals of the Kafka producer and explore how it selects the partition to which a message should be sent.
Understanding Kafka Partitions
To comprehend the partition selection process, it's crucial to first understand Kafka partitions. A Kafka topic is divided into one or more partitions, each representing an ordered and immutable sequence of records. Partitions allow for parallelism and scalability by enabling multiple consumers to read and process messages concurrently.
When a Kafka producer client sends a record to a topic, it needs to decide which partition to send it to. The partition selection algorithm is responsible choosing the partition.
Partitioning Strategies
Kafka provides flexible partitioning strategies that allow producers to control how messages are distributed across partitions. The choice of partitioning strategy has implications for data distribution, load balancing, and order preservation.
Key-based Partitioning: In key-based partitioning, the producer assigns a key to each message. The key is used to determine the target partition. Kafka guarantees that all messages with the same key will be written to the same partition, ensuring order preservation for those messages. This strategy is suitable when maintaining message order based on a specific key is crucial.
Round-robin Partitioning: In the absence of a key or if the producer explicitly chooses round-robin partitioning, Kafka will assign the message to a partition in a round-robin fashion. This strategy evenly distributes messages across all partitions, promoting load balancing. However, message ordering cannot be guaranteed as different partitions may receive messages in different orders.
In versions of Apache Kafka prior to 2.4, the partitioning strategy for messages without keys involved cycling through the partitions of the topic and sending a record to each one. However, this approach had drawbacks in terms of batching efficiency and potential latency issues.
To address this issue, Apache Kafka version 2.4 introduced a new partitioning strategy called "sticky partitioning." This strategy aims to assign records to partitions in a more efficient manner, reducing latency.
With sticky partitioning, records with null keys are assigned to specific partitions, rather than cycling through all partitions. This approach leverages the concept of "stickiness," where records without keys are consistently routed to the same partitions based on certain criteria.
This is dependent on linger.ms and batch.size properties.
Even when linger.ms is 0, the producer will group records into batches when they are produced to the same partition around the same time.
For more details check this link : https://www.confluent.io/blog/apache-kafka-producer-improvements-sticky-partitioner/
Custom Partitioning: Kafka allows the implementation of custom partitioners by extending the org.apache.kafka.clients.producer.Partitioner interface. Custom partitioners enable the producer to define their own logic for selecting the target partition based on message attributes, algorithms, or business requirements.
Partition Selection Process:

For more details check this video : A Kafka Client’s Request: There and Back Again by Danica Fine - YouTube
Understanding how the Kafka producer selects the partition for messages is essential for designing efficient and reliable data pipelines. By leveraging key-based partitioning, round-robin partitioning, or custom partitioners, producers can control data distribution, load balancing, and message ordering according to their specific requirements.
Whether you need strict order preservation based on keys or load balancing across partitions, Kafka's partition selection process offers the flexibility to tailor your message publishing strategy to suit your use case. By optimizing partitioning, you can fully leverage Kafka's scalability and high-throughput capabilities.
Partition selection is just one step that are involved that happens when you call kafkaTemplate.send()
public void sendMessage(String topic, String message) {
kafkaTemplate.send(topic, message);
System.out.println("Sent message: " + message + " to topic: " + topic);
}
Other steps that happen, when the producer sends a message and that message is persisted in Kafka brokers and the producer receives the acknowledgement.
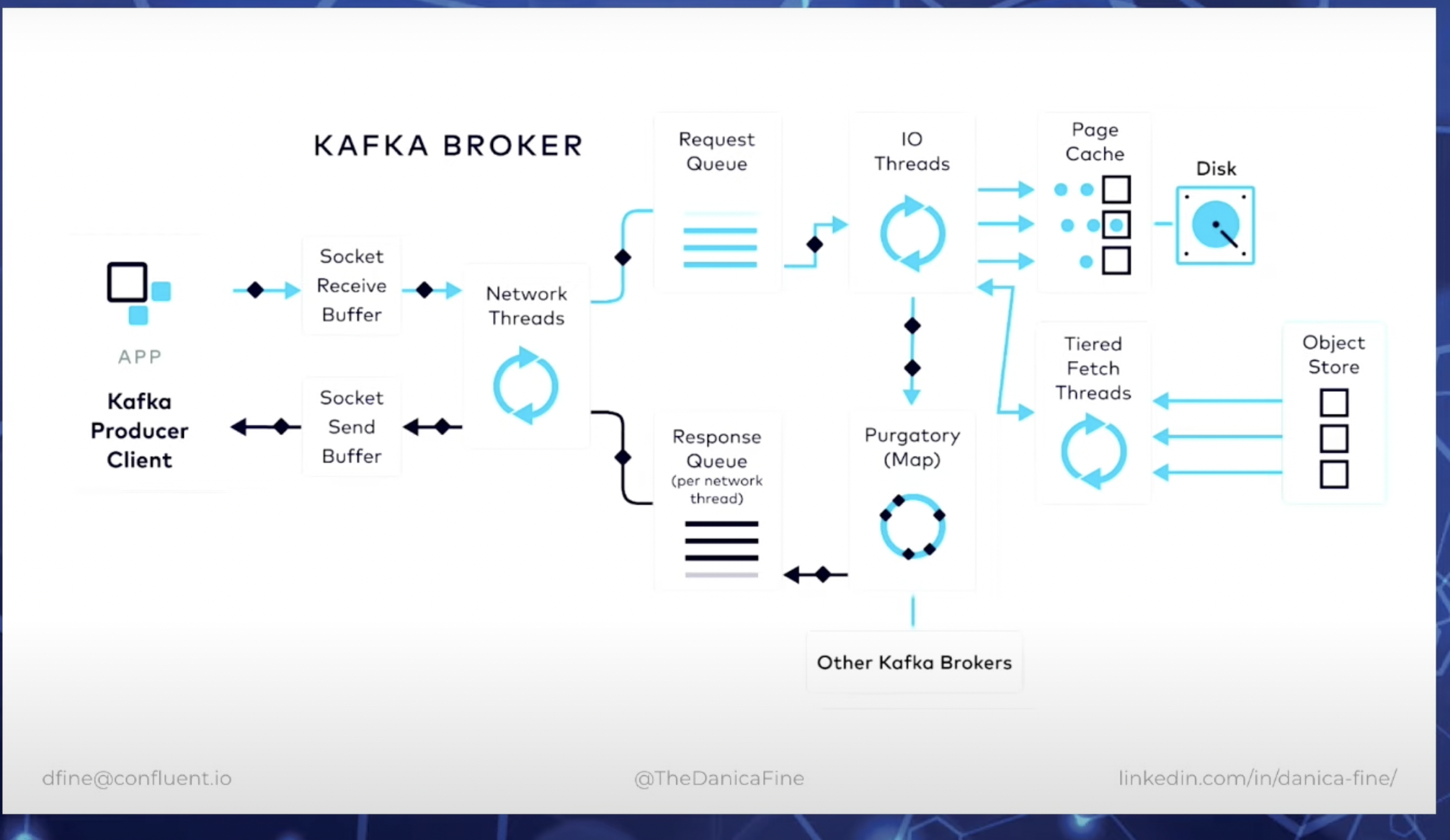
Message is converted to a ProducerRecord object before it is sent.
public class ProducerRecord<K, V> {
private final String topic;
private final Integer partition;
private final Headers headers;
private final K key;
private final V value;
private final Long timestamp;
DefaultPartitioner strategy
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster,
int numPartitions) {
if (keyBytes == null) {
return stickyPartitionCache.partition(topic, cluster);
}
// hash the keyBytes to choose a partition
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
If you liked this blog, you can follow me on twitter, and learn something new with me.




